

Over the past decade, our capacity to use software to extract meaningful information from textual data has grown significantly.
Understanding, processing, and generating natural language are now essential concepts in conversational Artificial Intelligence (AI), mainly due to the emergence of next- generation Transformer language models.
Fundamentally, language models use statistical and probabilistic methods to predict the sequence of words or phrases in any given language. Simply put, a language model is an algorithm that has learned to read and write in a specific language, including but not limited to English, German or Spanish.
To do this with perfect accuracy, an AI language model is trained on large amounts of textual data to the point where it can reliably recognise and replicate patterns and relationships between the relevant words and phrases.
And the latest breakthroughs in the field of Natural Language Processing are helping to drive the growth in AI and underpin how language models will drive future developments in this field.
Language Models, A Short History
Language models have moved through several iterations since the 1970s, with each new approach driven by the increasing hardware sophistication and the ongoing research of language model software engineers.
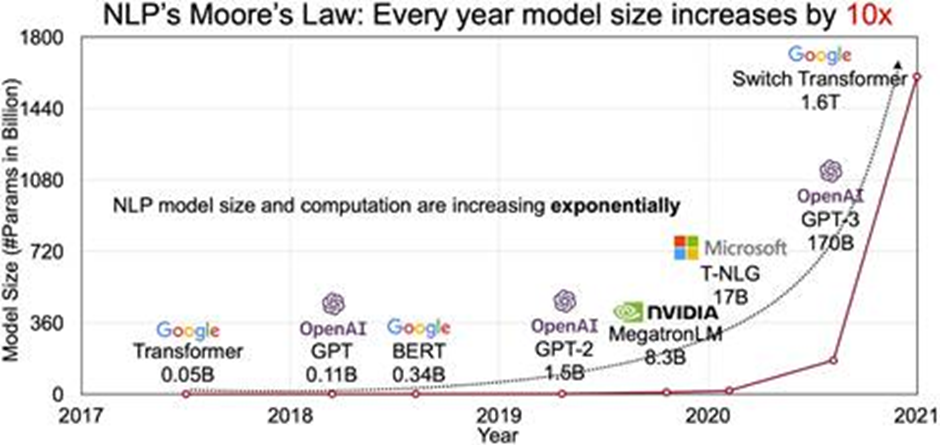
Reference: https://indiaai.gov.in/
Rule-Based Models emerged in the early days of language modelling research. Here software designers relied on rule-based systems to generate and understand language based on predefined rules to determine the meaning of a sentence and then generate appropriate responses.
Rule-based models are used in various fields and applications where a set of predefined rules can be used to classify or process data. Here are some examples of where rule-based models are used:
- Spam filtering: Rule-based models can be used to detect and filter spam emails based on certain trigger words or patterns in the content.
- Chatbots: Rule-based models can be used to create simple chatbots that can respond to specific user inputs or queries based on predefined rules.
- Fraud detection: Rule-based models can be used to identify potential fraudulent transactions based on certain rules or patterns in the data.
- Information retrieval: Rule-based models can be used to extract specific information from text documents or web pages based on predefined rules.
- Medical diagnosis: Rule-based models can be used in medical diagnosis to identify certain symptoms or conditions based on predefined rules or decision trees.
Overall, rule-based models are useful in situations where a set of explicit rules can be defined to automate decision-making or classification tasks. However, they may not be suitable for tasks that require more complex reasoning or handling of uncertain or noisy data.
These rules would be programmed into the model, and when it encounters a new email, it would analyze the email according to these rules to determine whether it’s spam or not.
Statistical Models developed in the 1980s and 1990s used probabilistic techniques to estimate the likelihood of observing a particular sequence of words or phrases. An early example was the n-gram model. This approach models sequences of words using the Markov Process, which determines the probability of observing a series of ‘n’ words in simple text. For example, a bigram model would calculate the probability of the next word given only the previous word, while a trigram model would calculate the probability of the next word given the previous two words.
Neural Models emerged in the 2000s, based on artificial neural networks. These simulate the structure and function of the human brain to perform complex tasks. They use Artificial Neural Networks (ANNs) to learn and improve over time by analysing large amounts of data. Examples of neural models include Recurrent Neural Networks (RNNs), Convolutional Neural Networks (CNNs), and more. These models were able to learn the underlying structure of language, allowing them to generate more realistic and natural-sounding text. LSTM or Long Short-Term Memory is the most commonly used type of RNN, that is designed to capture long-term dependencies in sequential data. LSTMs are popular because they are effective in capturing long-term dependencies in sequential data, a challenge that commonly arises in language modeling and other tasks.
Transformer Models have emerged as a bleeding-edge approach to language modelling in recent years. Unlike traditional neural systems, which process sentences sequentially, Transformers are advanced neural models that use a self-attention mechanism to identify important relationships between words in a sentence.
A Transformer model can efficiently process all the words in a phrase simultaneously, allowing it to comprehend the overall relationships between the words. In this way, Transformers generate more coherent and contextually relevant responses, significantly improving the quality of language generation and machine translation.
The evolution of transformer dates back to 2017, when the first transformer was introduced, which was an upgrade on previous neural network models like the RNN and CNN, in capturing long-range dependencies in sequential data.
BERT (Bidirectional Encoder Representations from Transformers) was introduced in 2018 which was trained on large corpus of text data and achieved state-of-the-art performance on several natural language processing tasks such as question answering, text classification, and named entity recognition.
Refer the following link for explanation of BERT
Following BERT was XLNet model which is another transformer-based model which captures dependencies in both forward and backward directions, similar to BERT.
BERT is a bidirectional model that is pre-trained using two main objectives: masked language modeling (MLM) and next sentence prediction (NSP). MLM randomly masks some of the words in a sentence and trains the model to predict the original word given its context, while NSP trains the model to predict whether two sentences are consecutive or not. BERT uses a fixed sequence of tokens as input and has a fixed order of processing the input tokens. BERT uses a fixed sequence of tokens as input and has a fixed order of processing the input tokens.
On the other hand, XLNet is a generalized autoregressive model that is pre-trained using permutation language modeling (PLM). Unlike BERT, which uses a fixed sequence of tokens, XLNet uses all possible permutations of the input tokens and predicts the probability of each token given its previous tokens, regardless of their order.
The GPT-3 (Generative Pre-trained Transformer 3) model family from Open AI gained prominence in 2020. The renowned ChatGPT is powered by this exact variant. It is a unidirectional autoregressive model with 175B parameters that only uses the encoder. (much bigger than BERT). The only GPT-3 versions that can currently be fine-tuned are the Da Vinci, Curie, Ada, and Babbage models. phamax’s Ariya AI-powered digital assistant employs the DaVinci model of GPT-3 to recognize entities and intentions.
Following GPT-3 is GPT-3.5, which performs task with better quality, longer output, and consistent instruction-following than the curie, babbage, or ada models.
Next is GPT-4, which is a large multimodal model (accepting text inputs and emitting text outputs today, with image inputs coming in the future) that can solve difficult problems with greater accuracy than any of our previous models, thanks to its broader general knowledge and advanced reasoning capabilities.
NLP Capabilities
Language models play a vital role in Natural Language Processing (NLP), a subfield of Artificial Intelligence that focuses on understanding and processing everyday human language inputs, either spoken or via text. Applications made possible by NLP include interactive chatbots, sentiment analysis, named entity recognition, and text classification.
Uses of NLP comprise
- Speech Recognition models that help computers understand spoken language, enabling applications such as speech-to-text transcription, voice assistants, and speech analytics.
- Machine Translation models that can translate text from one language to another. Their training in multiple languages helps to bridge the gap between differing grammar rules and word orders.
- Text Generation models can create new original text based on a given prompt. These skills are helpful for chatbots, virtual assistants, and content generation, as recently demonstrated by ChatGPT.
- Text Summarisation models assimilate large amounts of text into a shorter, more digestible form, making them useful for accurately summarising news articles, legal documents, and research papers.
Language Modelling Use Cases
Language models can be used to build chatbots and virtual assistants to converse with users in natural language. Uses include providing customer service, conducting simple diagnoses or answering queries. Furthermore, language models can be domain trained on custom data to fit specific user or industrial purposes.
Modern language models can analyse text data and identify its underlying sentiment (using sentiment analysis). This is useful for monitoring social media commentary, customer reviews, and user feedback.
Machine translation models can translate text from one language to another. This is useful for communication and business purposes, such as translating documents or websites or breaking down language-based geographical barriers in global organisations.
Here are some trending examples:
- Drug discovery: Language models can be used to analyze large volumes of scientific literature and patent documents to identify potential drug targets or predict drug interactions.
- Clinical trial design: Language models can help researchers design more effective clinical trials by analyzing patient data and identifying patterns that could indicate optimal dosing regimens or patient cohorts.
- Medical information retrieval: Language models can be used to extract information from electronic medical records and other medical documents, making it easier for healthcare professionals to find relevant information quickly.
- Adverse event reporting: Language models can help automate the identification and reporting of adverse events related to drug use, improving patient safety and speeding up the reporting process.
- Drug safety monitoring: Language models can be used to monitor social media and other online sources for mentions of adverse events related to drugs, providing early warning of potential safety issues.
- Patient engagement: Language models can help personalize patient communications by analyzing patient data and tailoring messages to individual needs and preferences.
Overall, language modelling has the potential to revolutionize many aspects of the pharmaceutical industry, from drug discovery to patient engagement, by leveraging the power of natural language processing and machine learning.
If proof were needed that NLP language modelling has hit the mainstream, look no further than the recent launch of Microsoft 365 Copilot, which uses ChatGPT’s large language model to offer a conversational AI productivity tool based on a graphical analysis of a user’s MS 365 usage.
More Babel Towers To Topple
Language models are foundational for today’s conversational AI applications.
The evolution of this specialist branch of computer science has moved language modelling from rule-based models to probabilistic techniques like the n-gram model to neural networks through to today’s state-of-the-art Transformer models. This groundbreaking research has resulted in today’s pioneering language generation and machine translation capabilities.
With future advancements in language technologies and the immense amount of data collected from current users, future language models will undoubtedly become even more powerful. Soon exciting new applications and use cases will emerge not only in commerce but in how everyone will conduct their lives.


